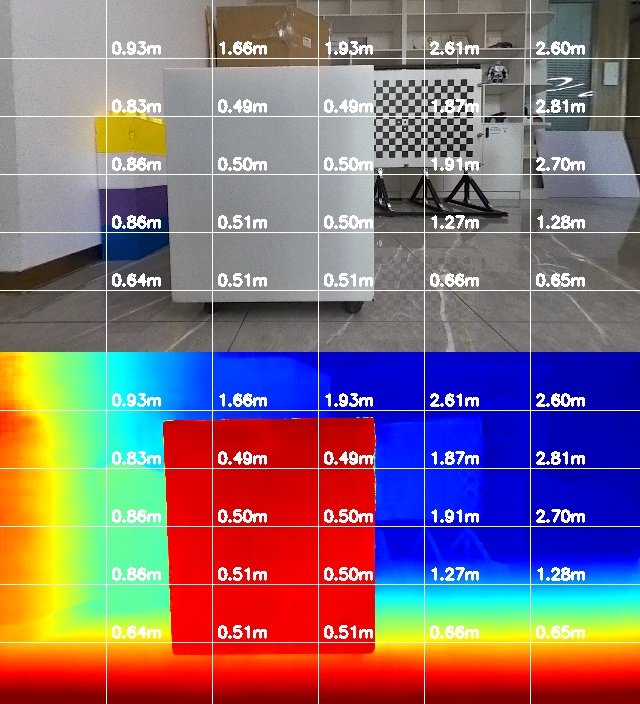
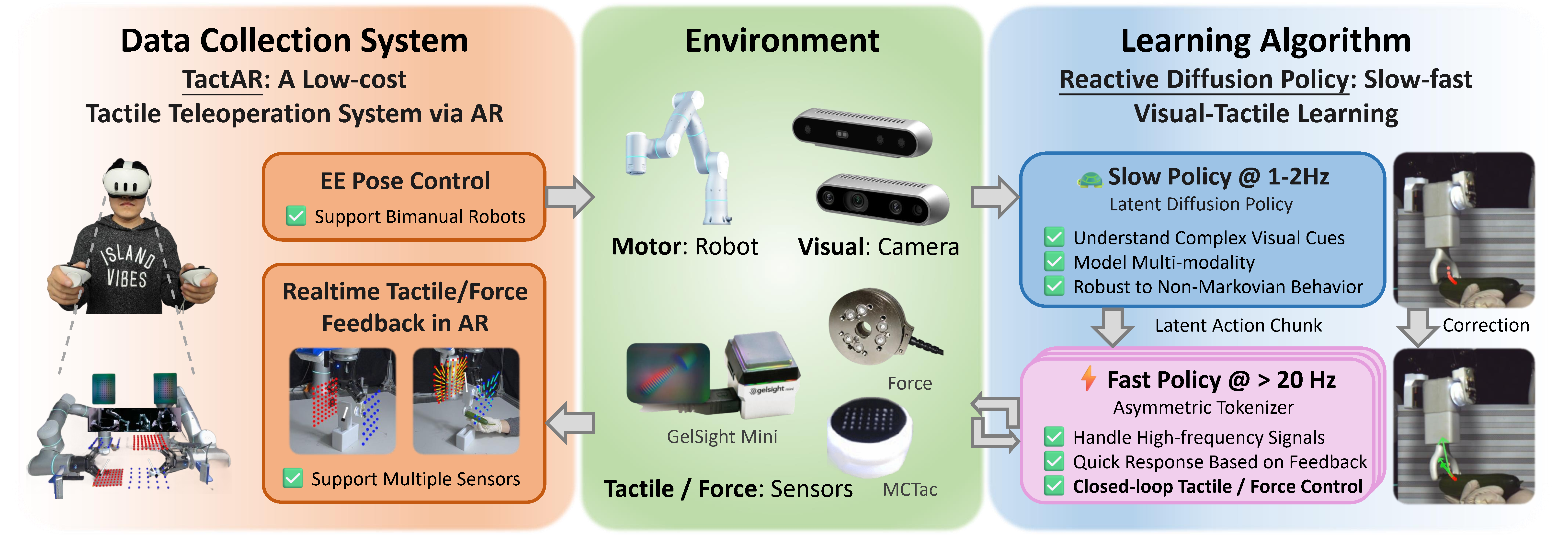
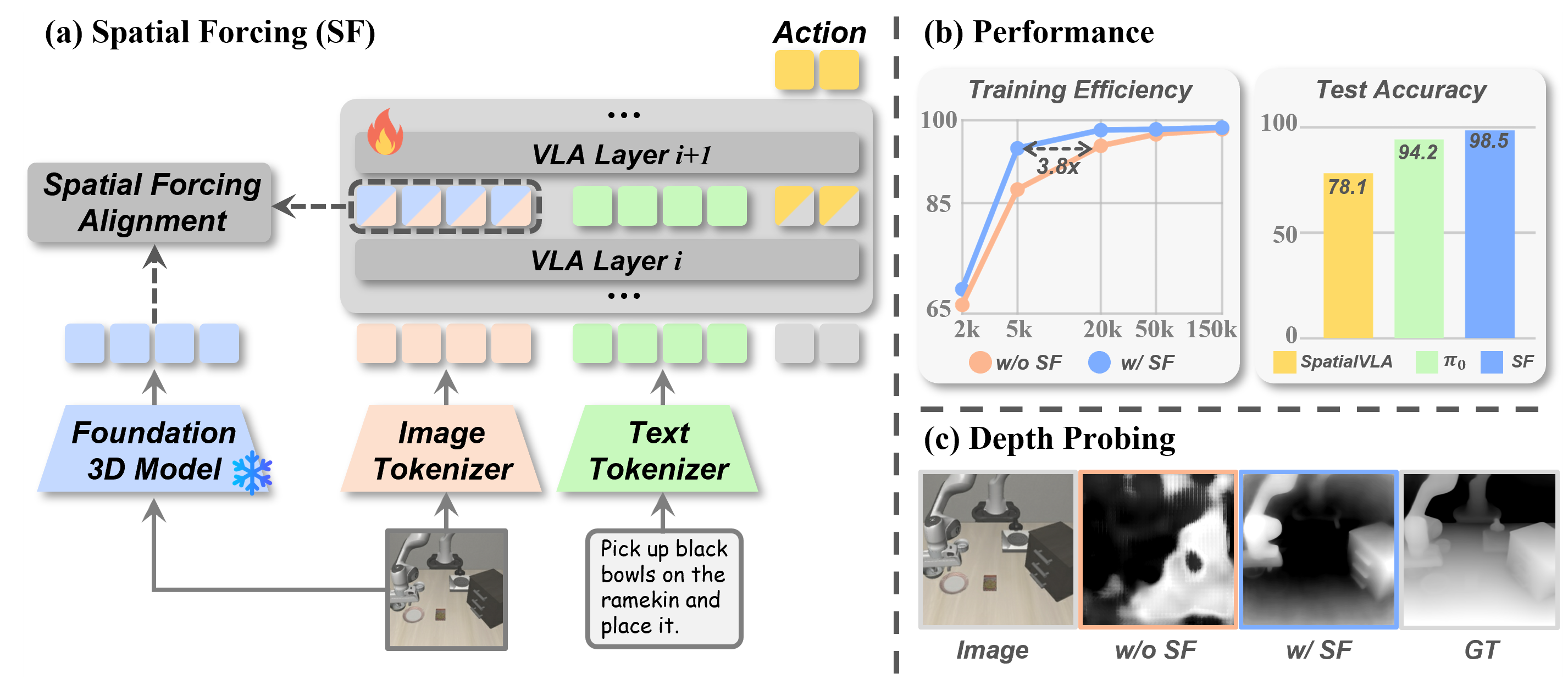
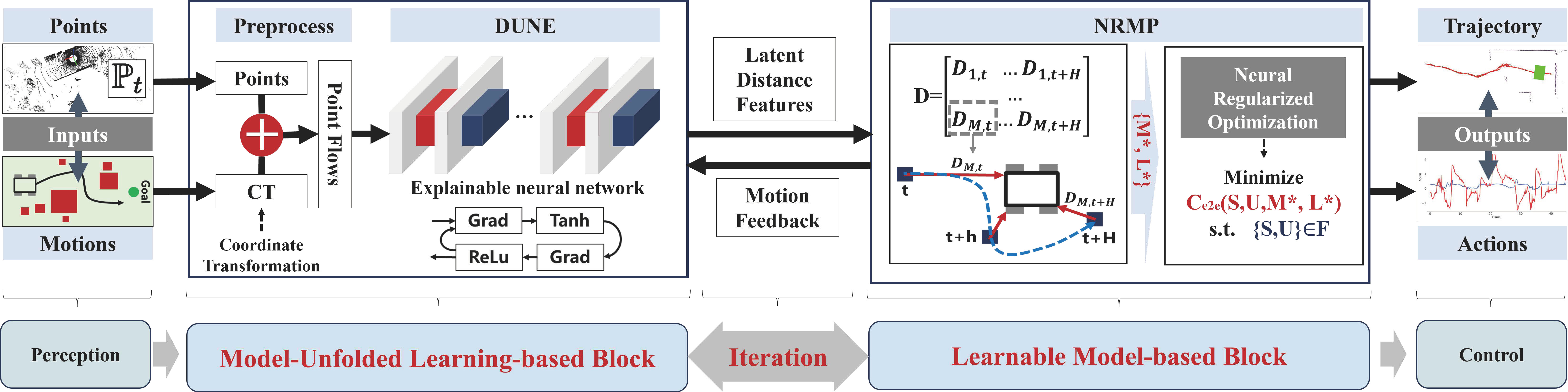
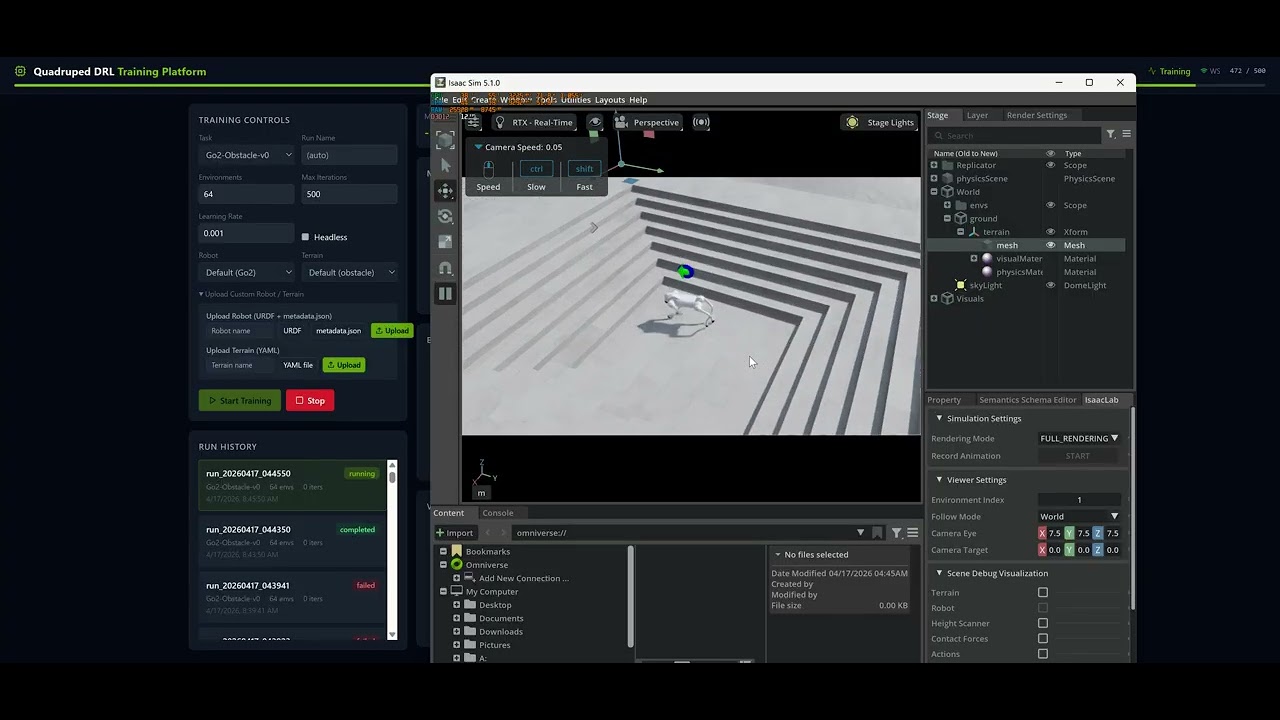
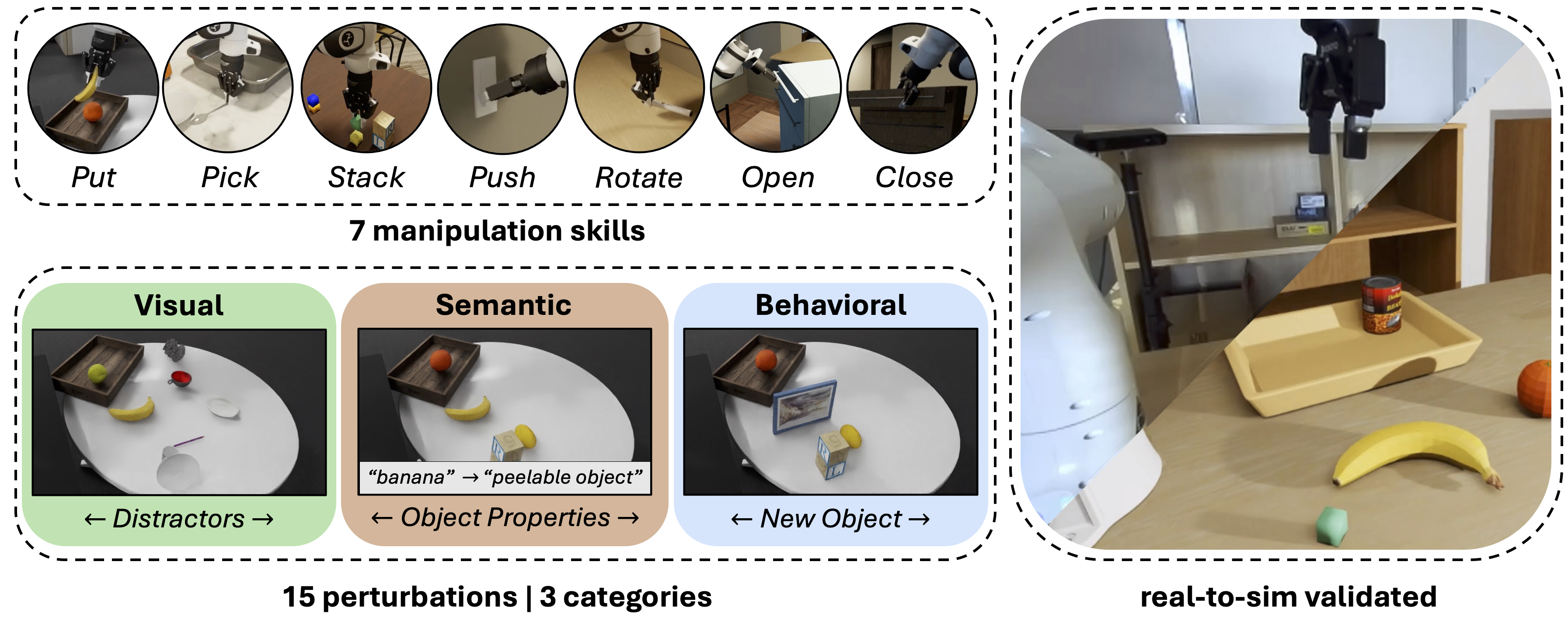
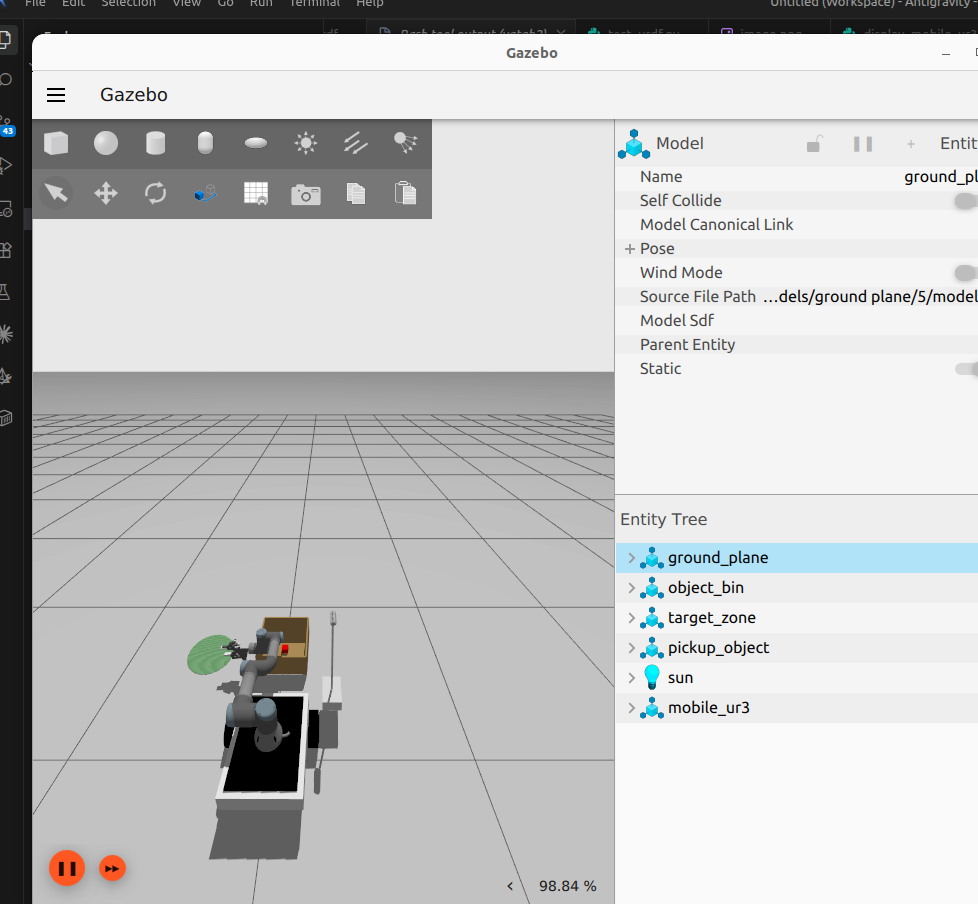
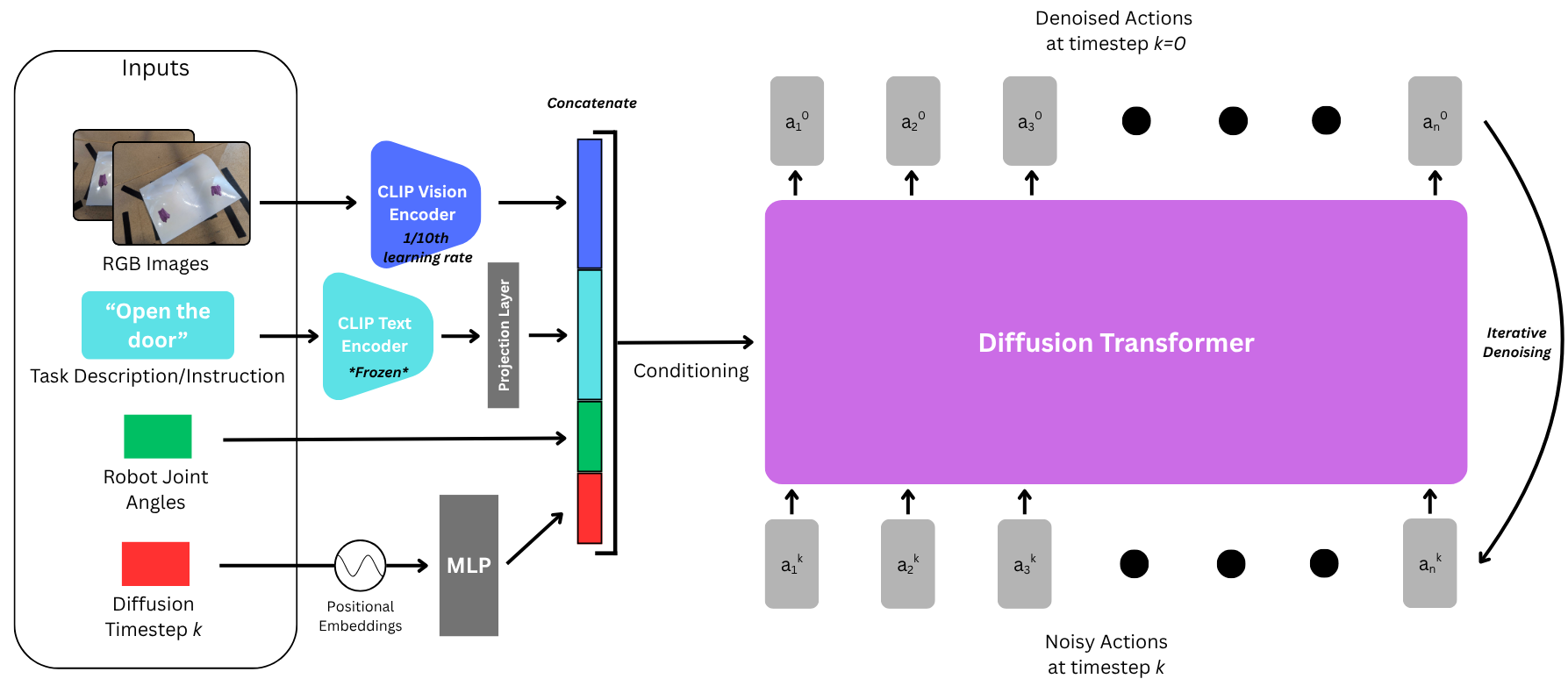
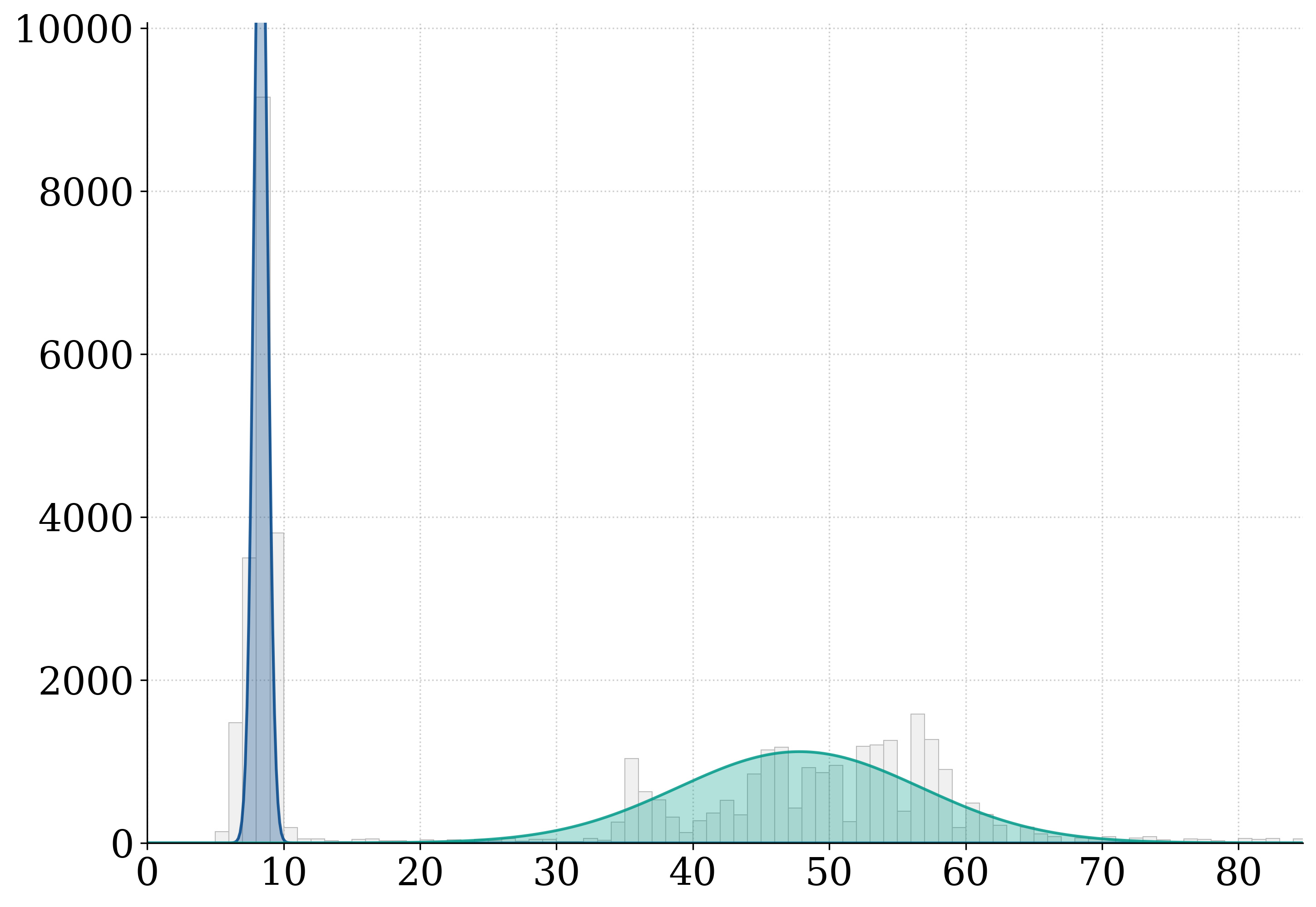
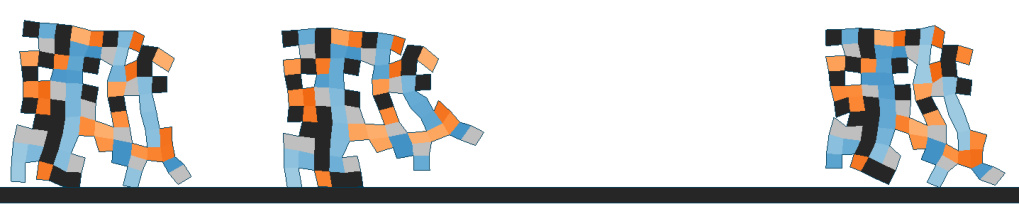
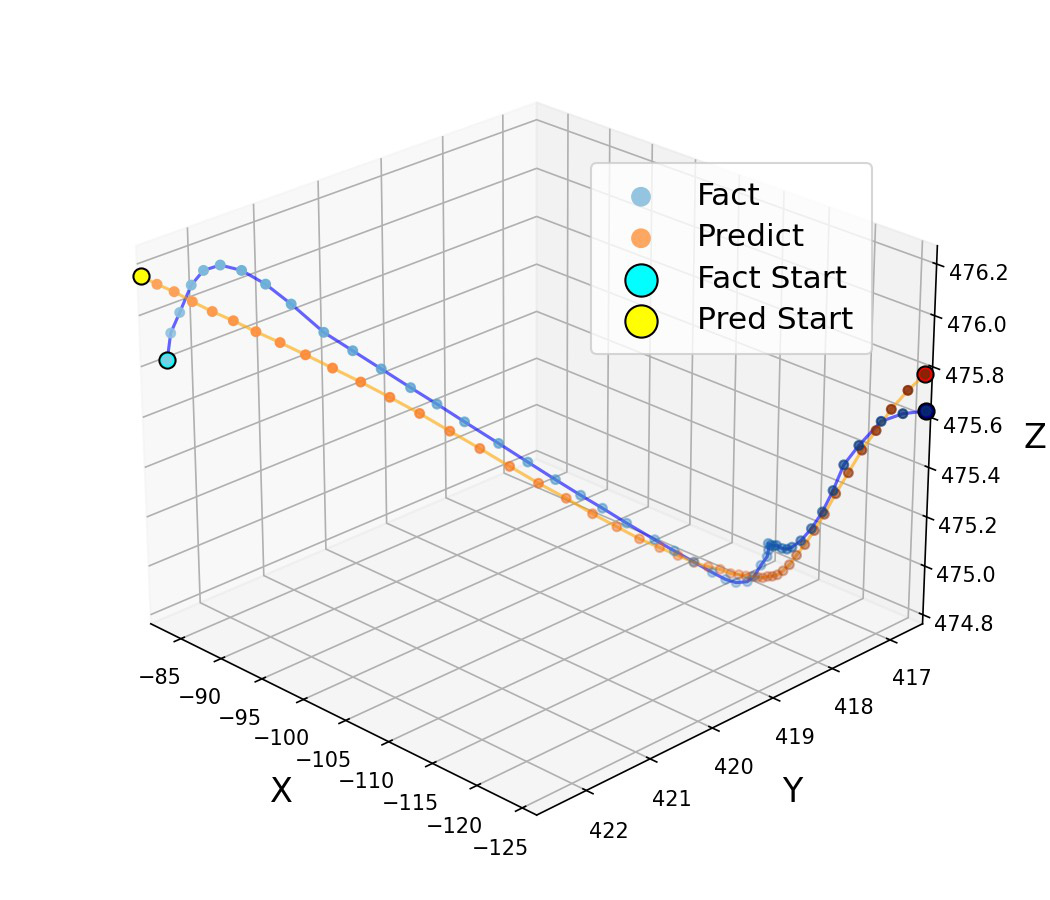
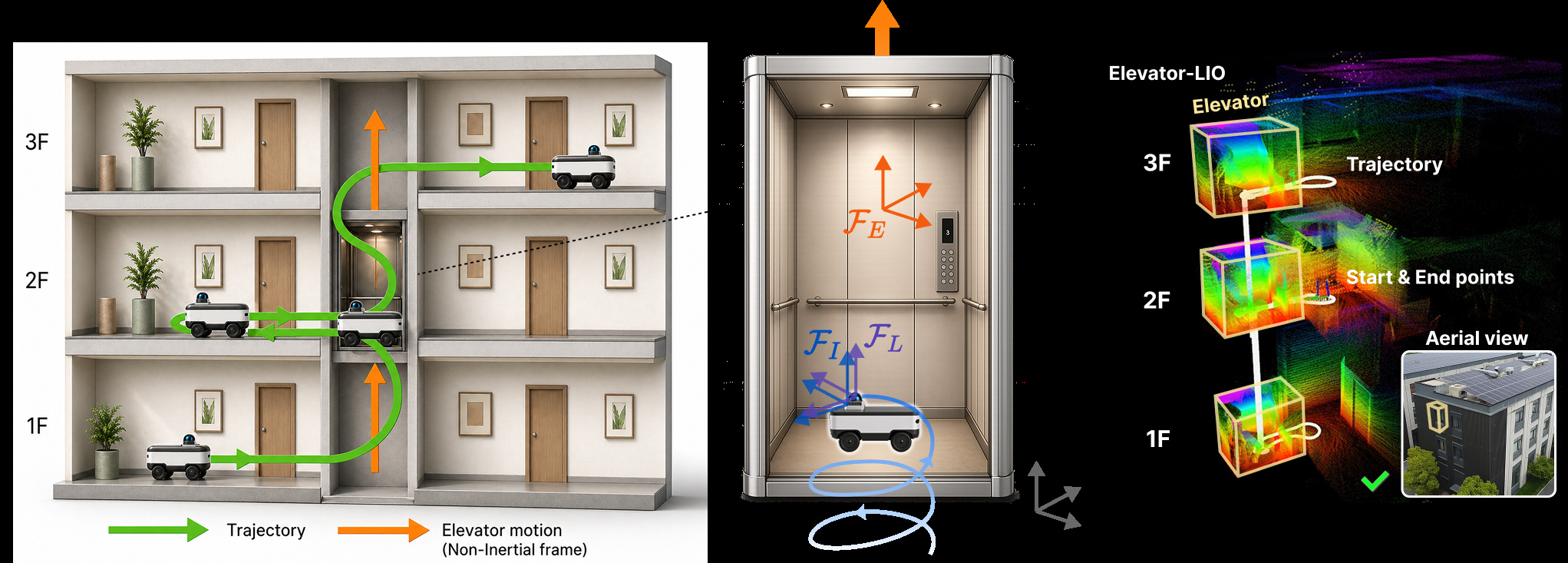
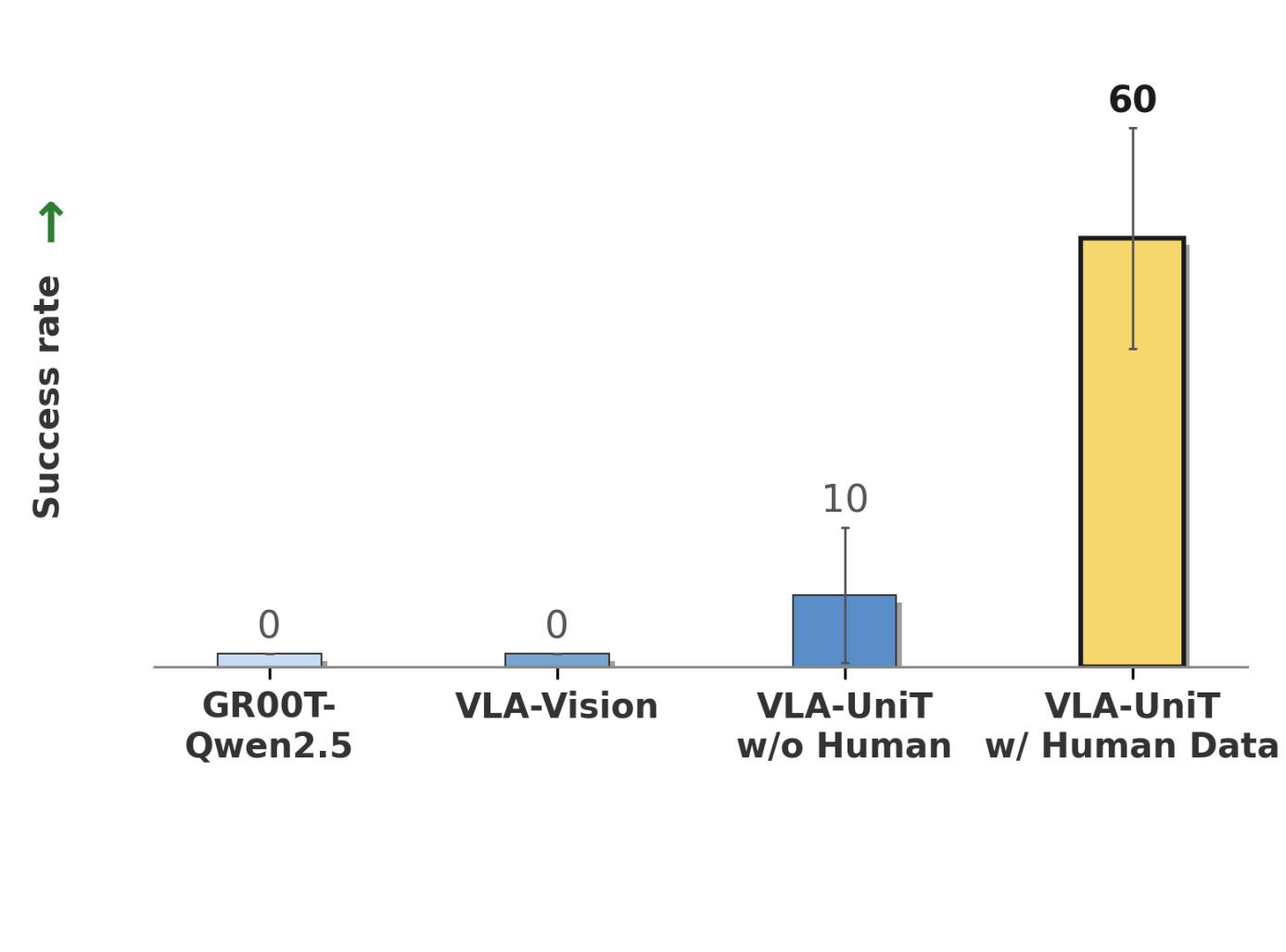
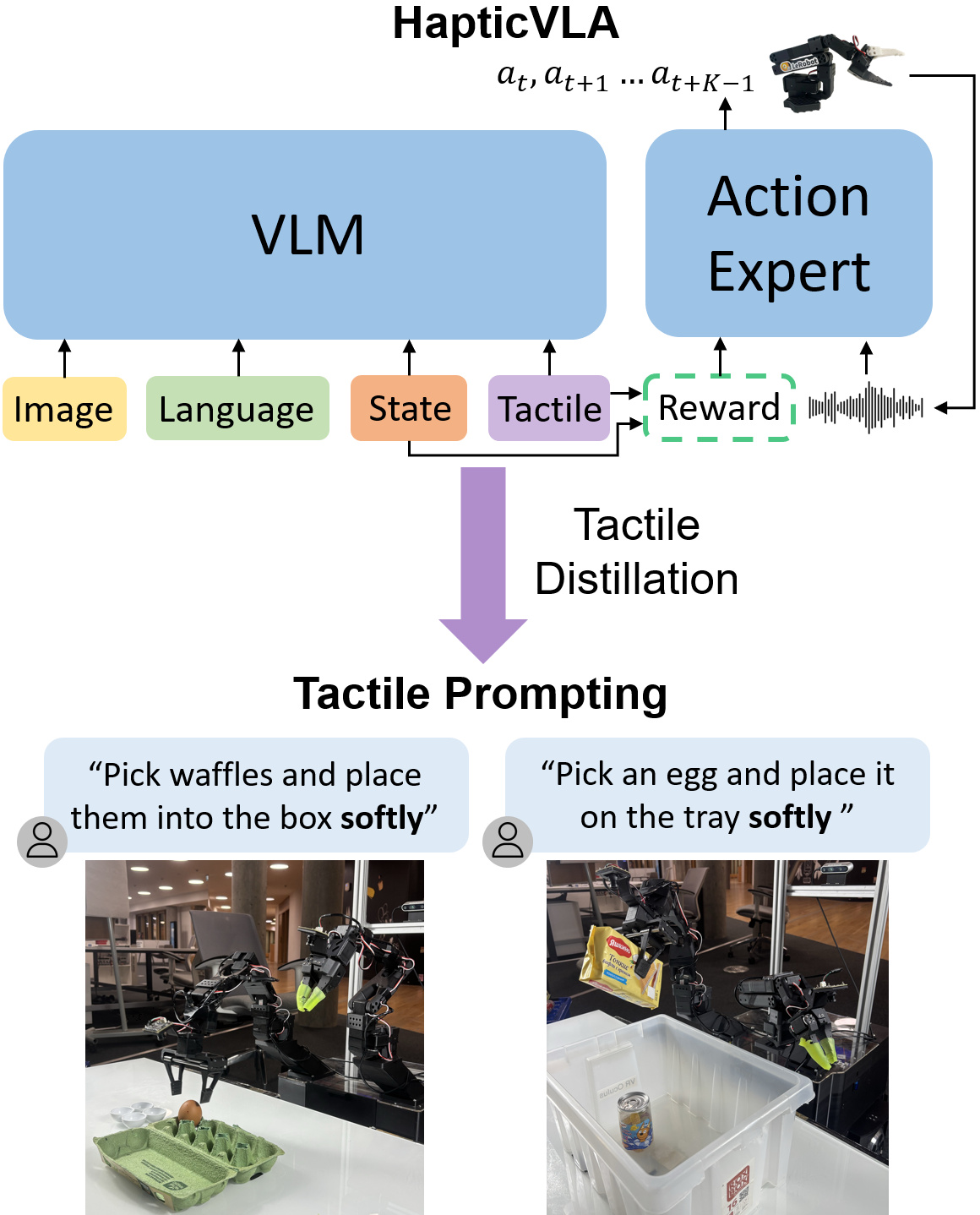
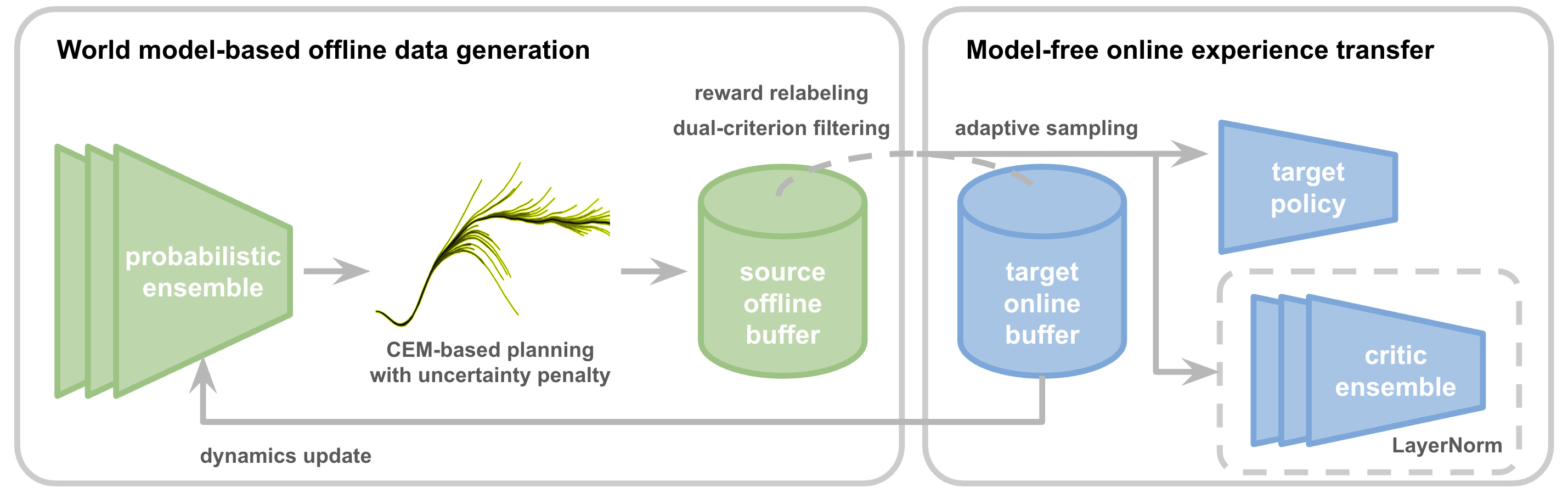
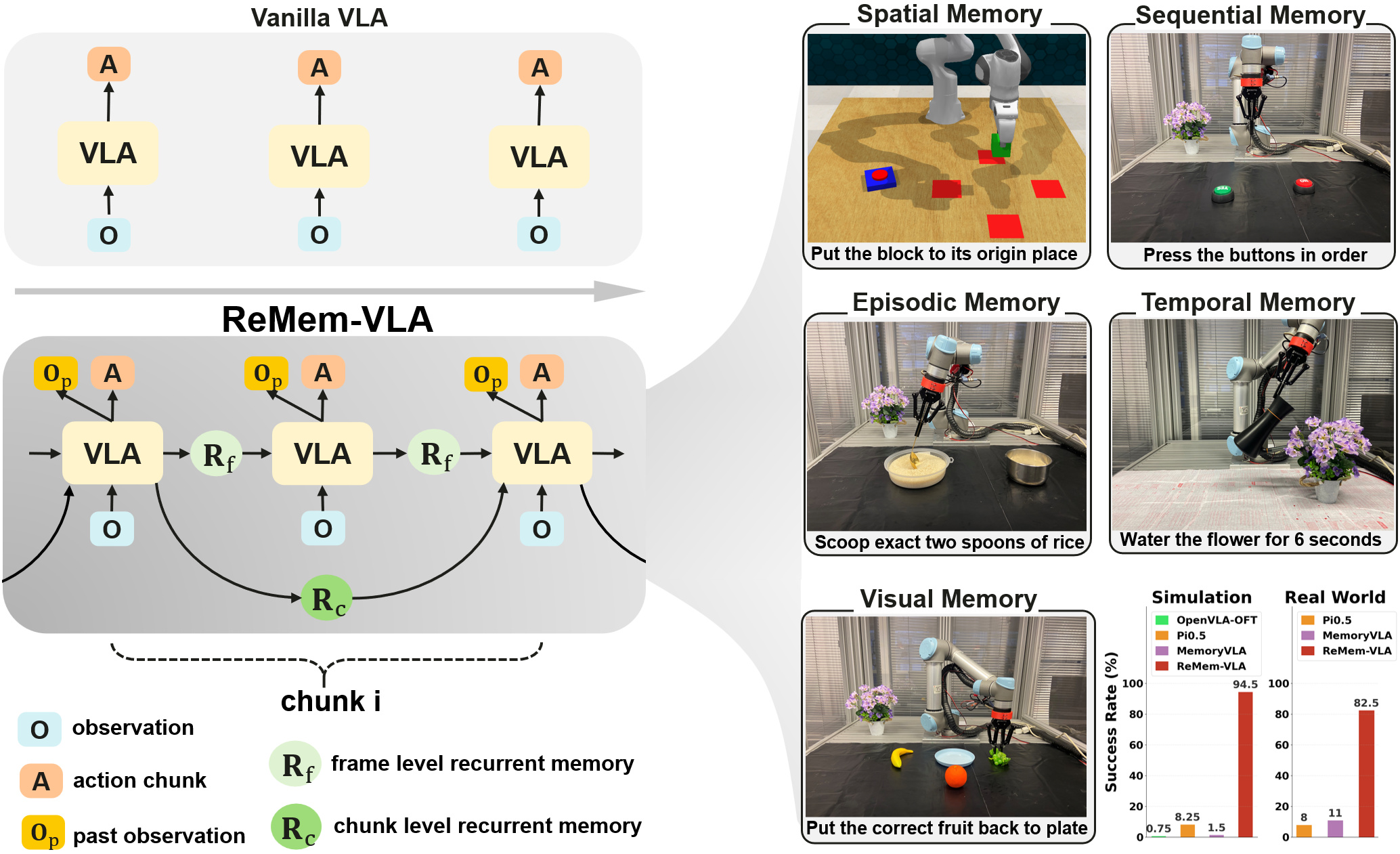
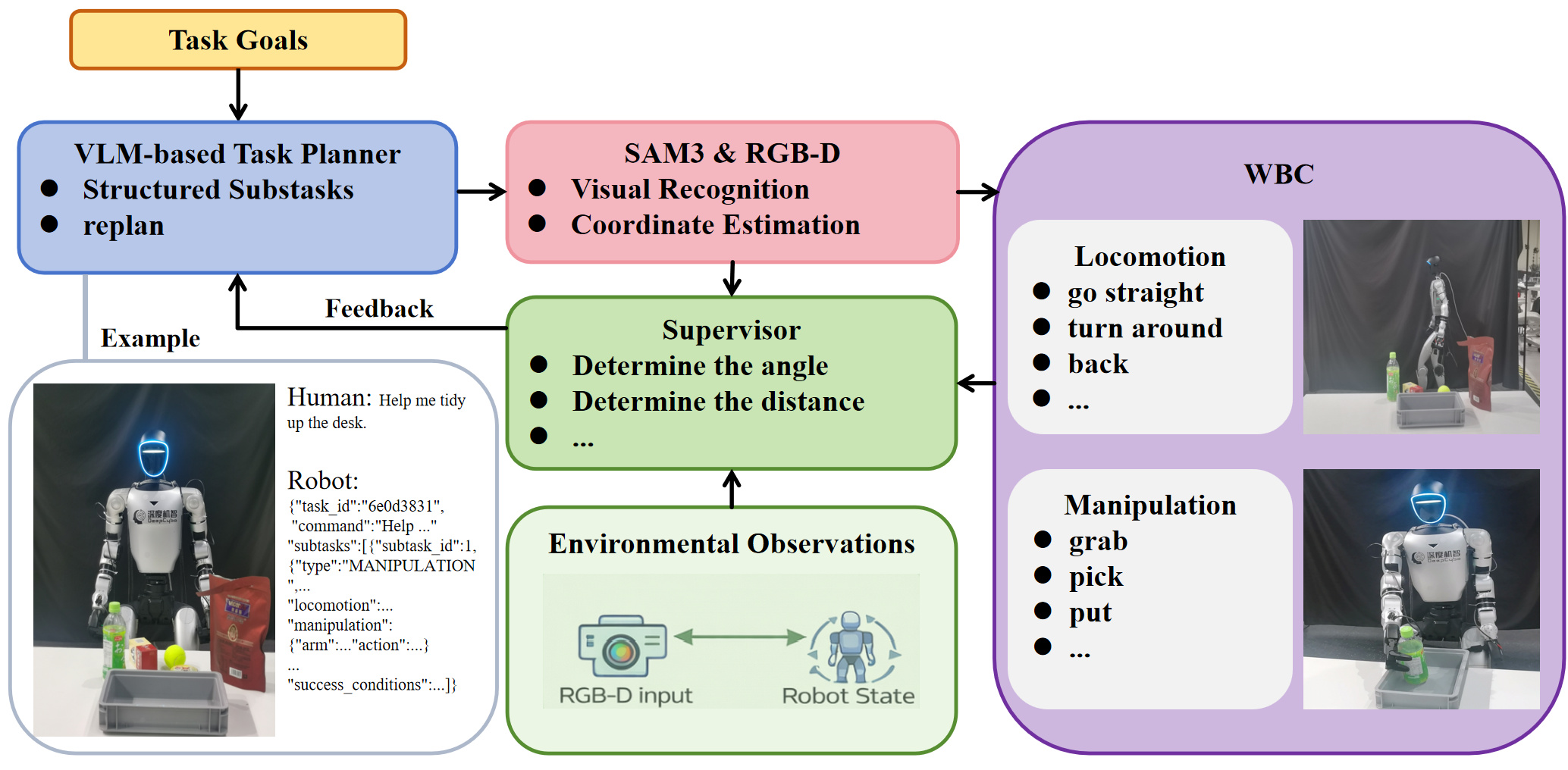
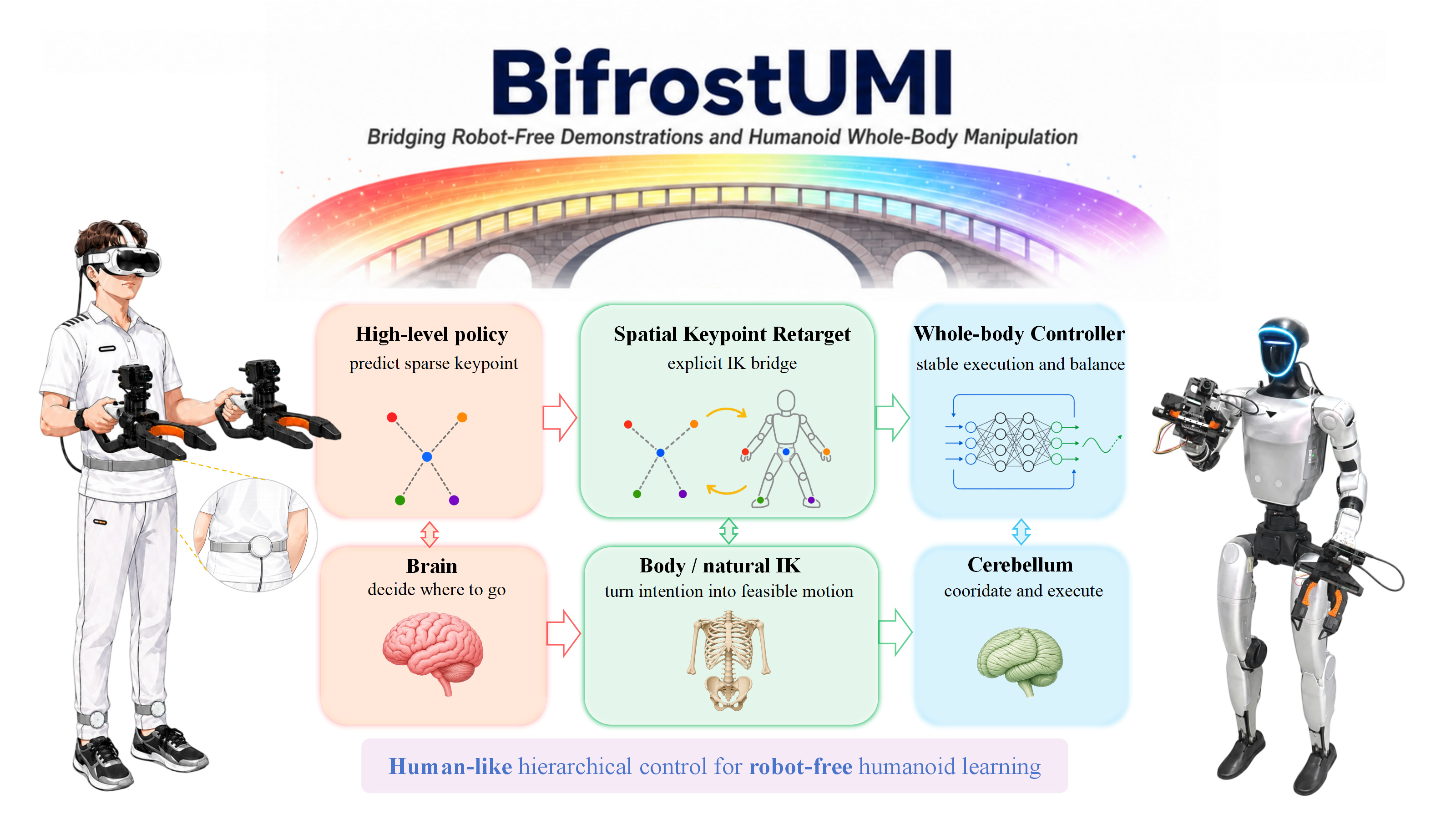
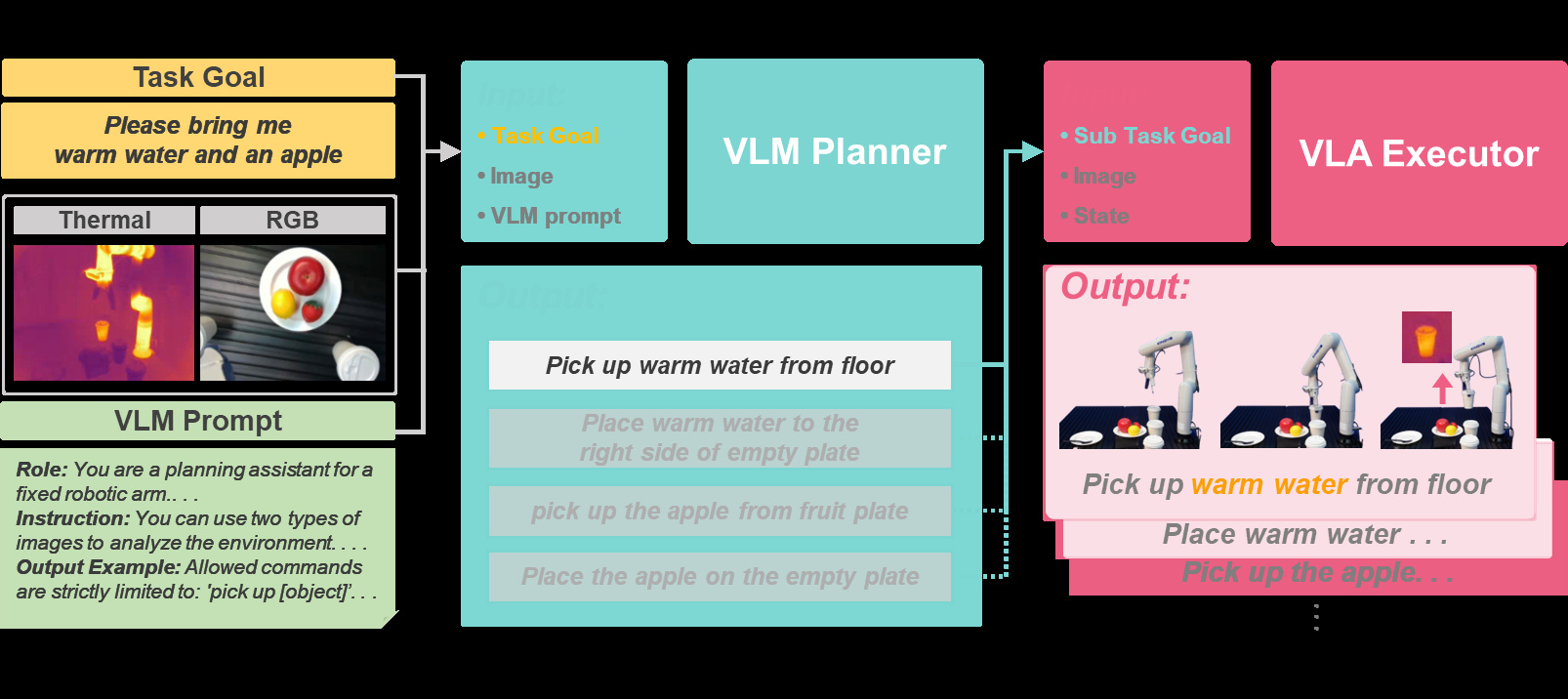
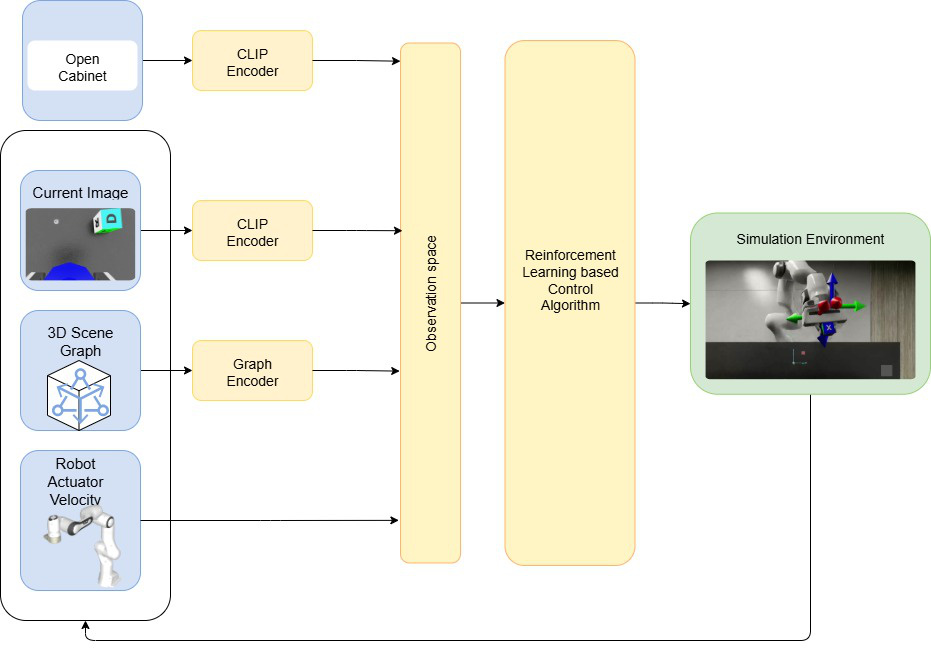
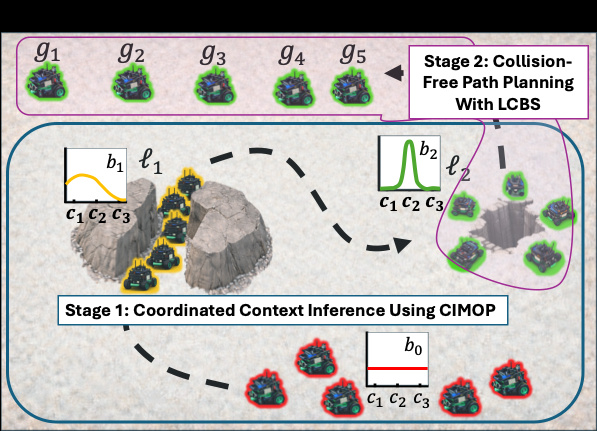
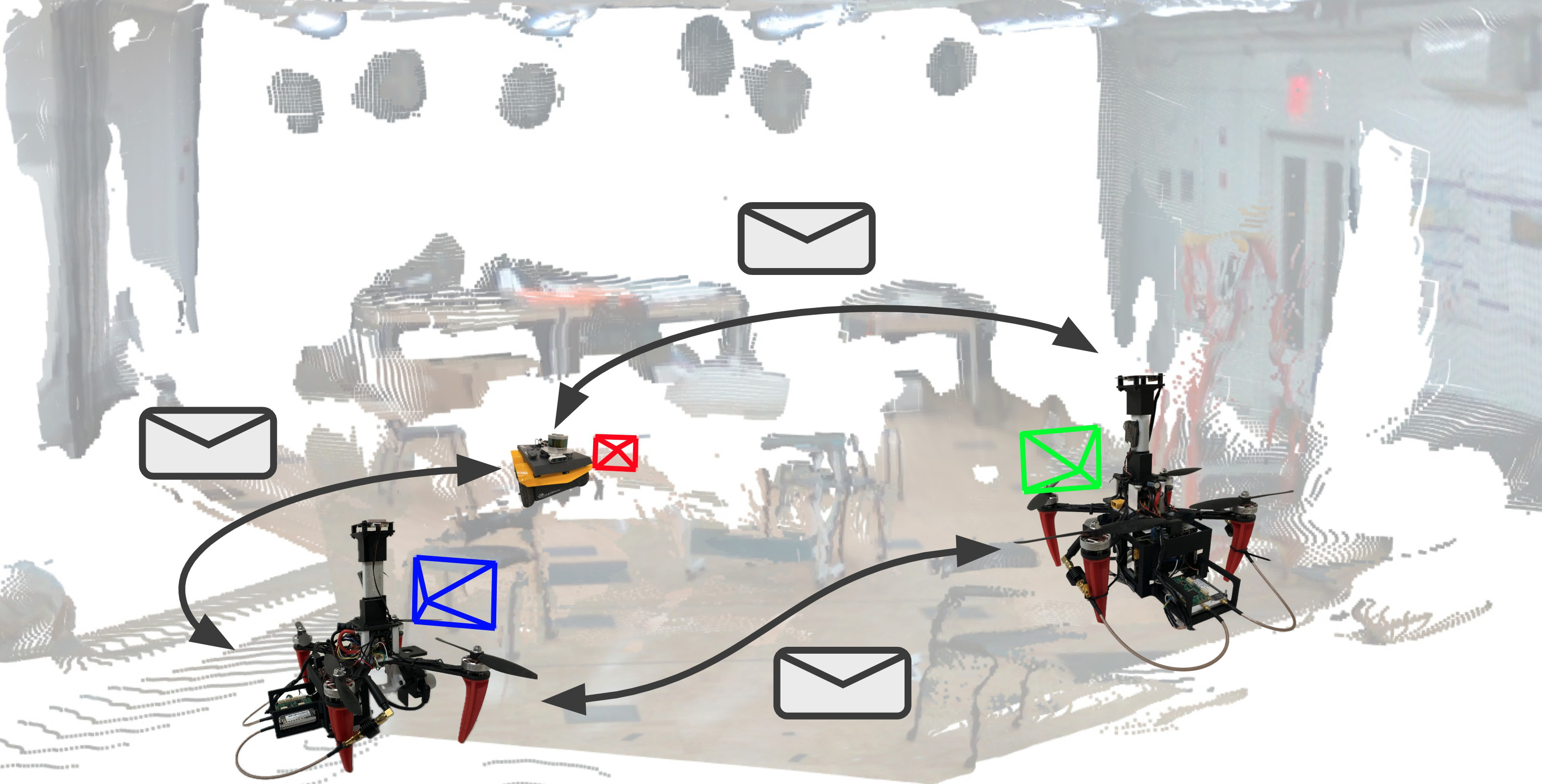
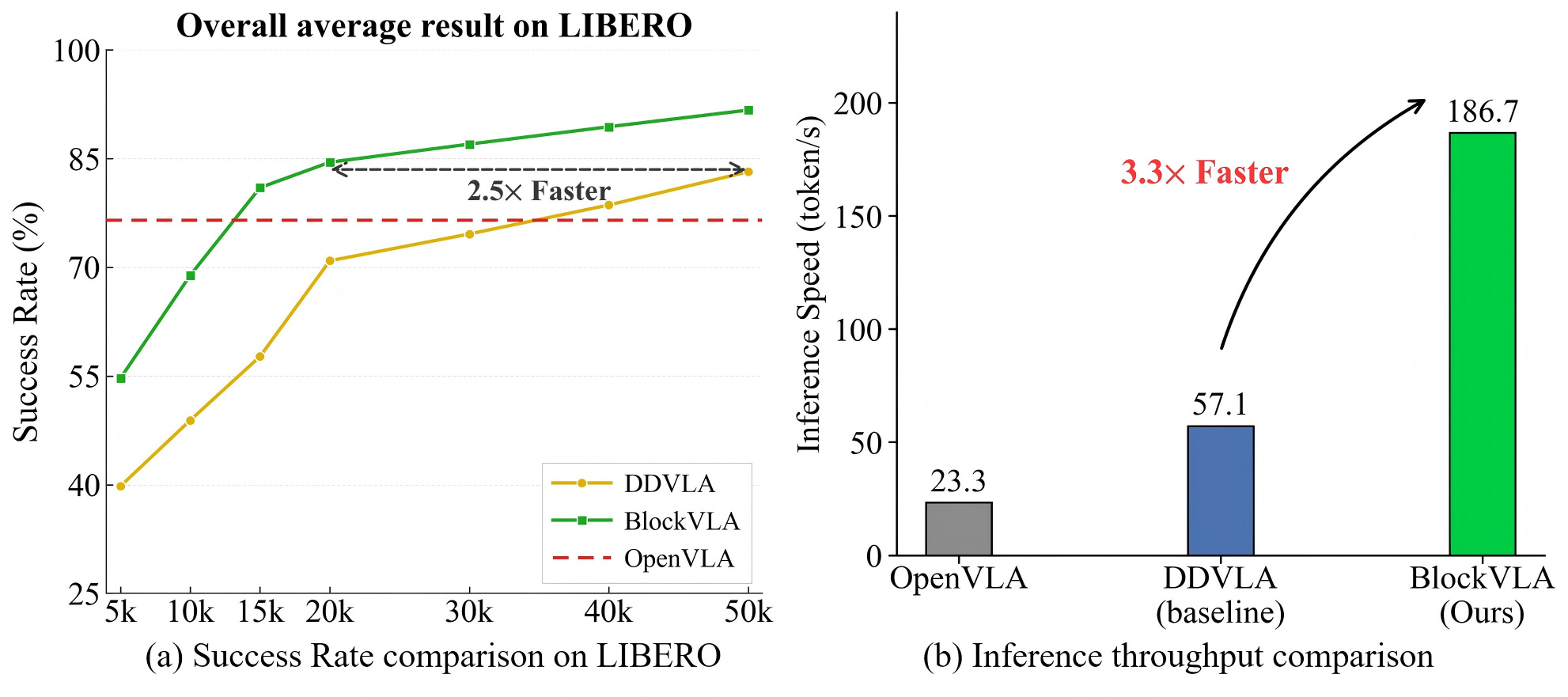
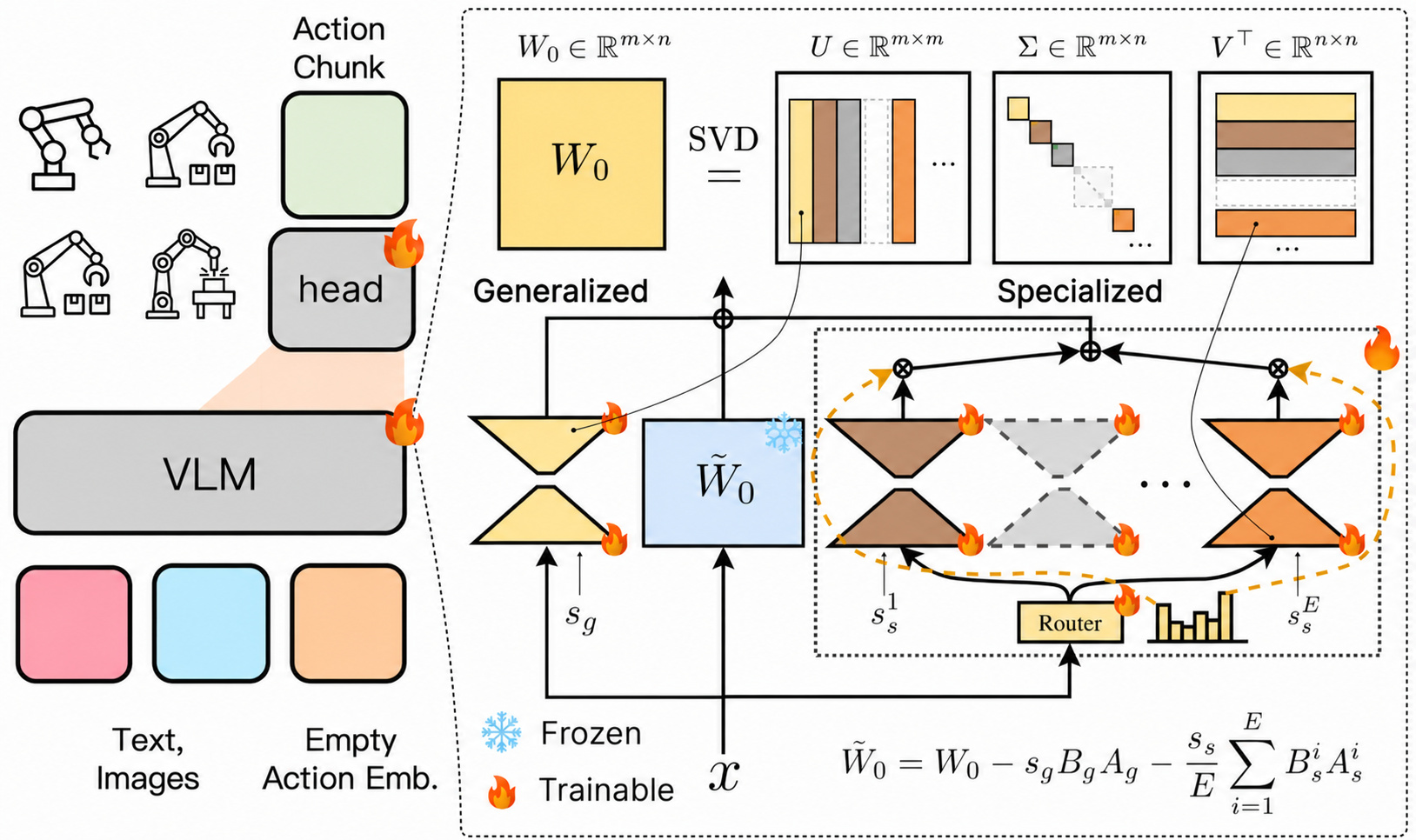
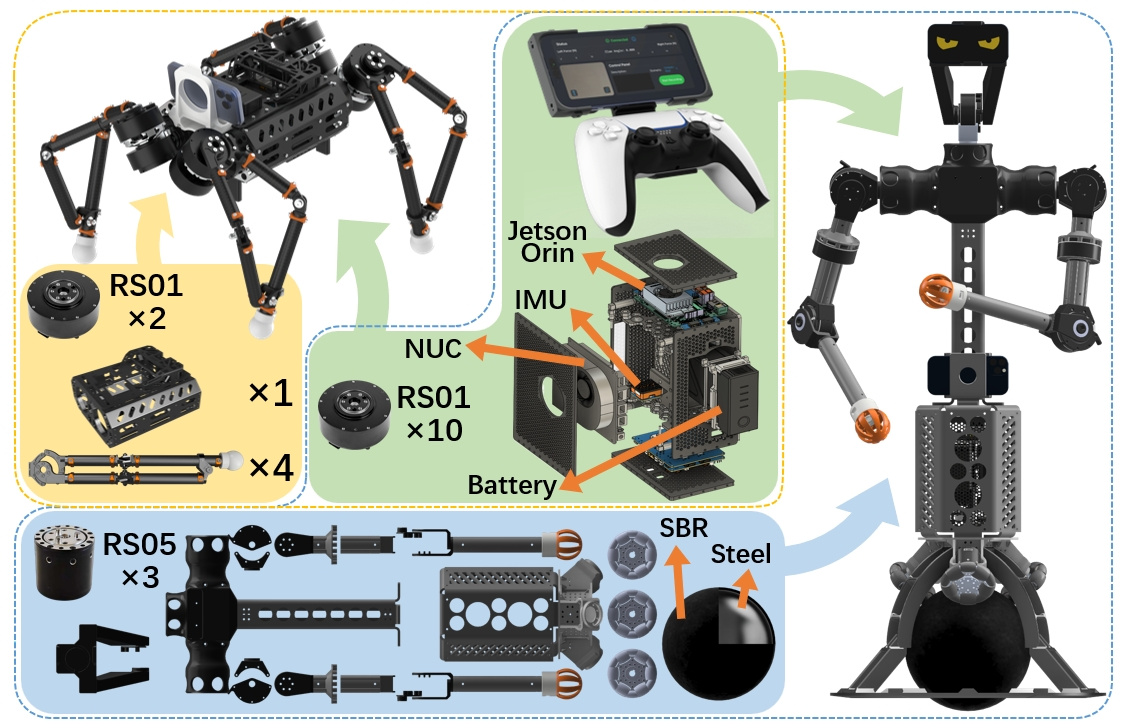
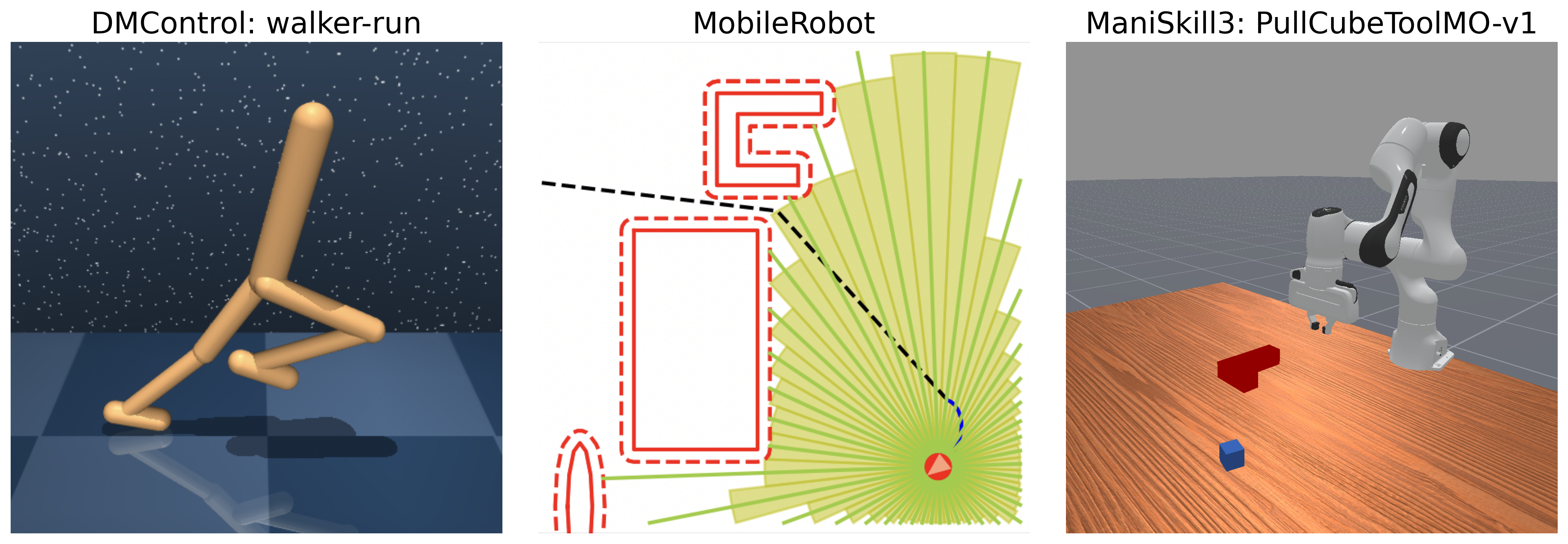
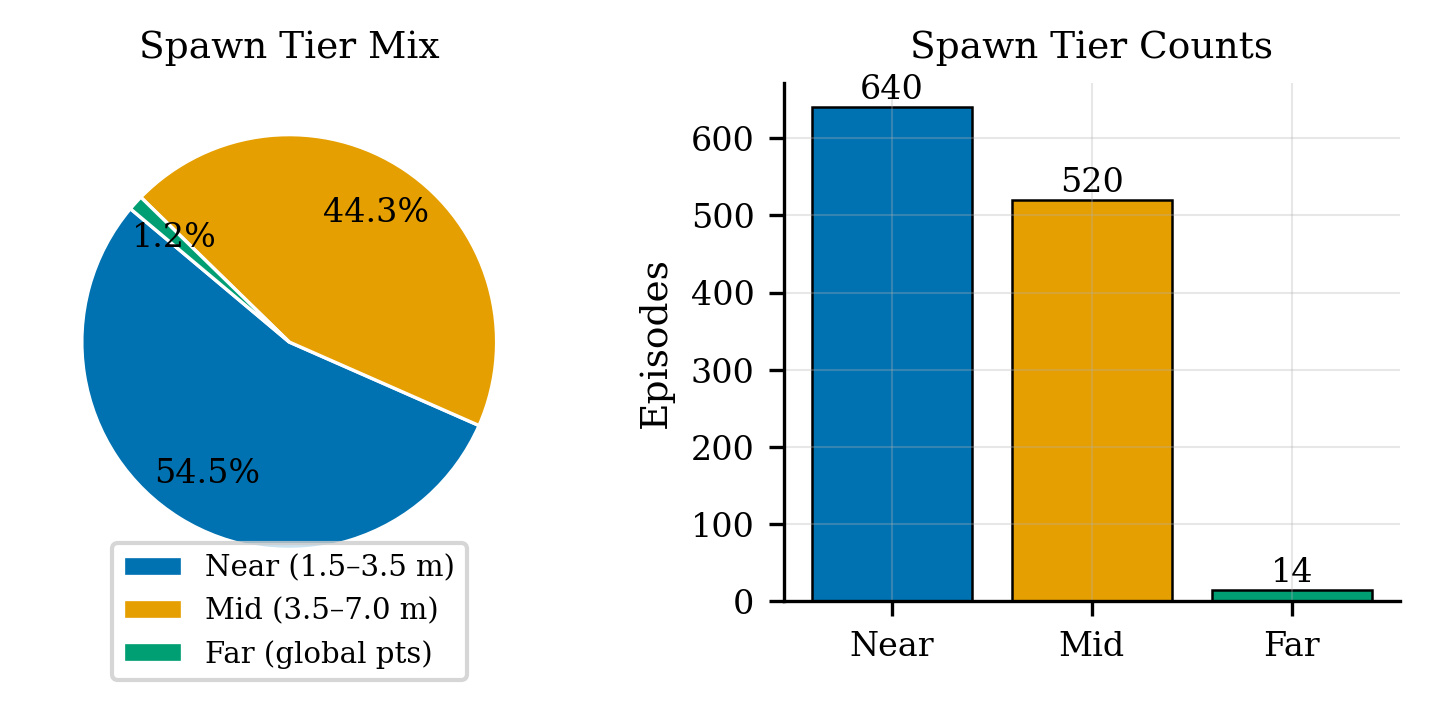
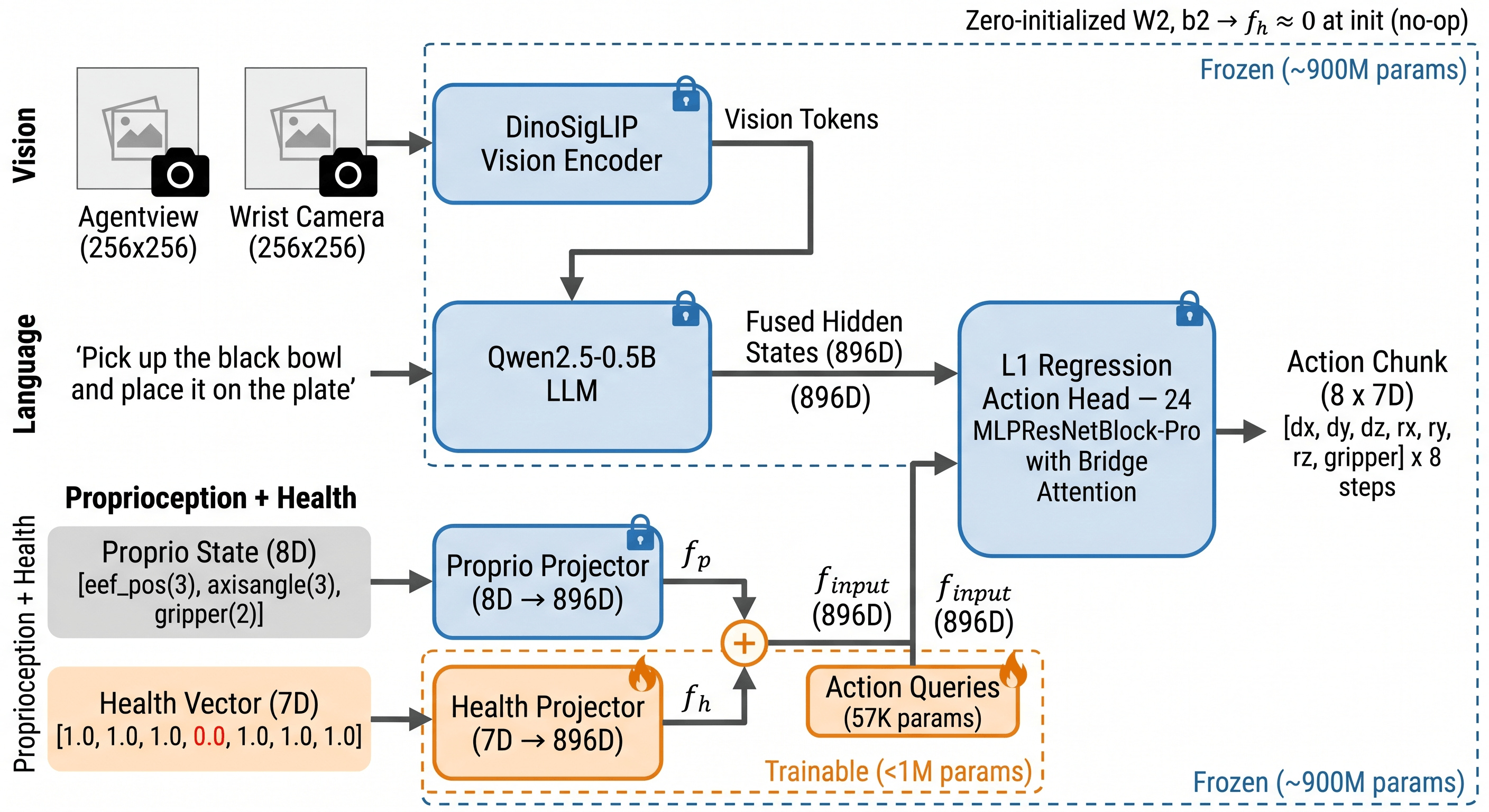
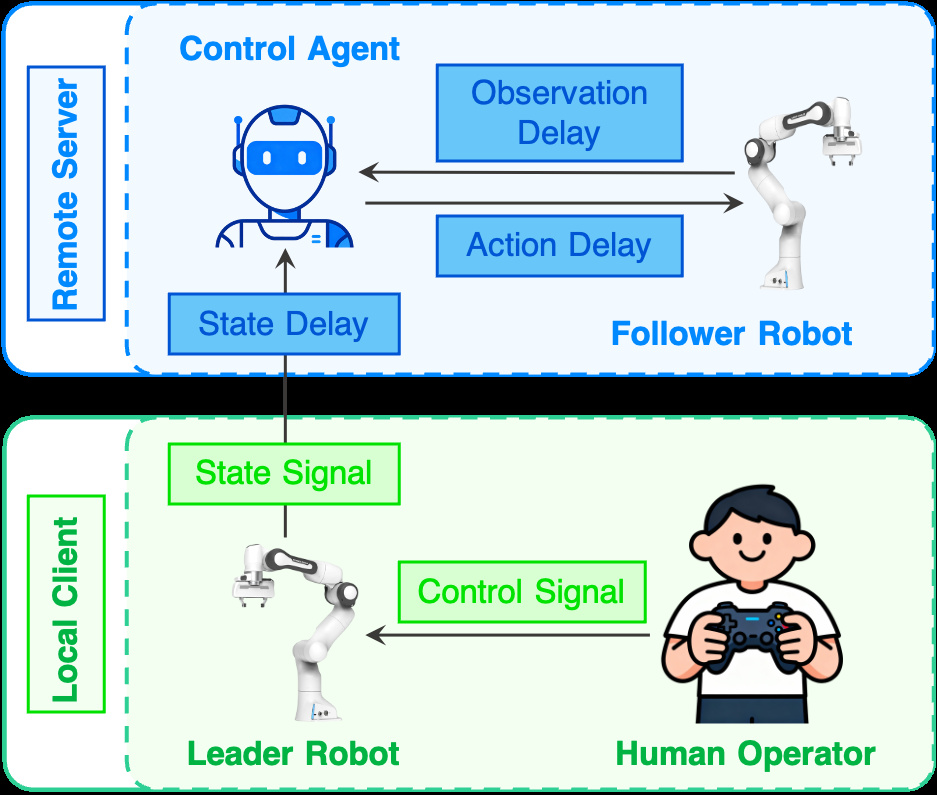
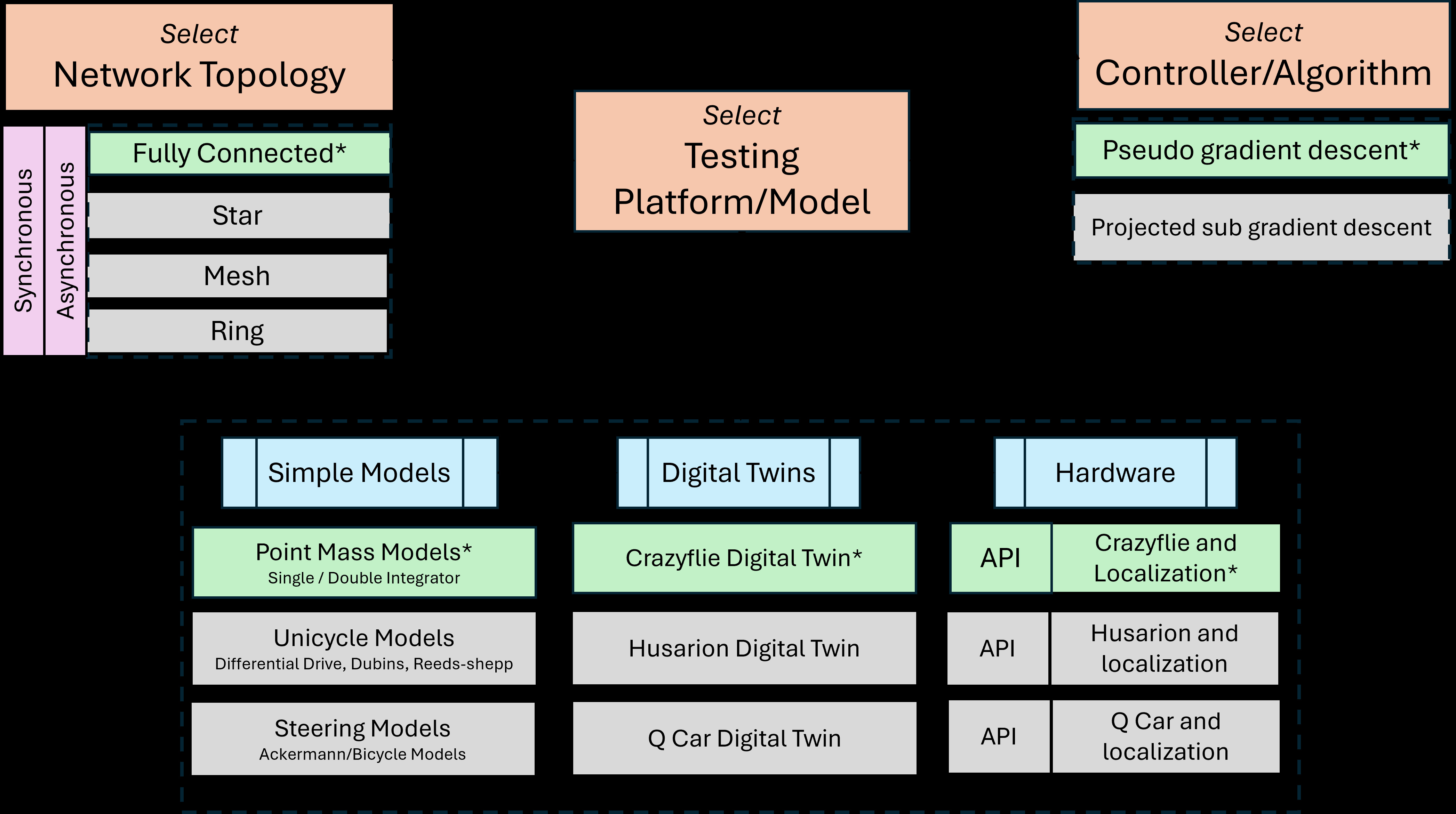
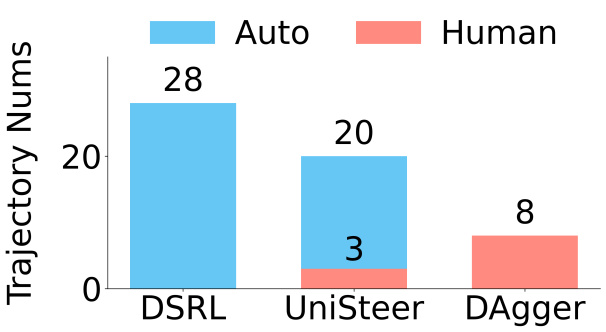
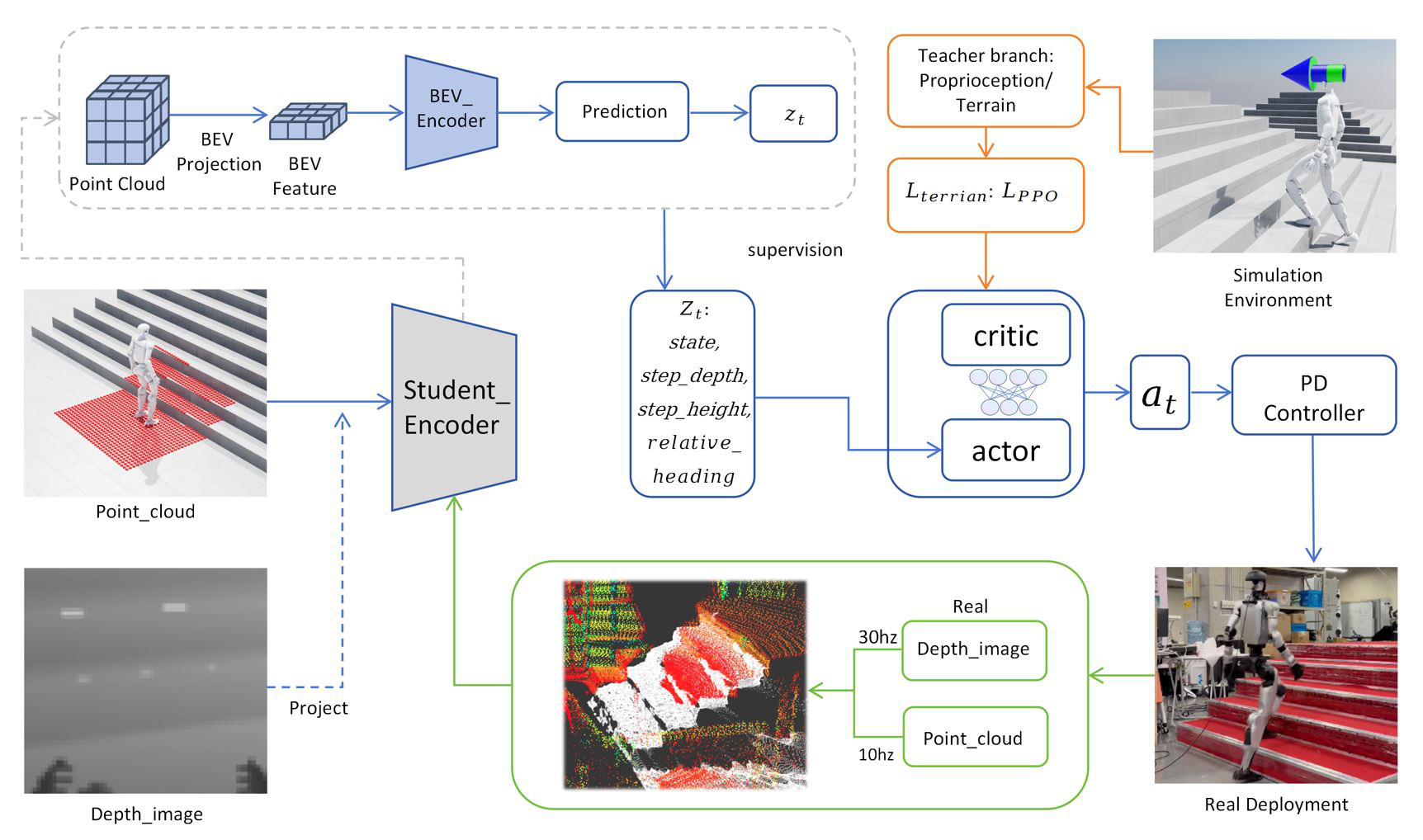
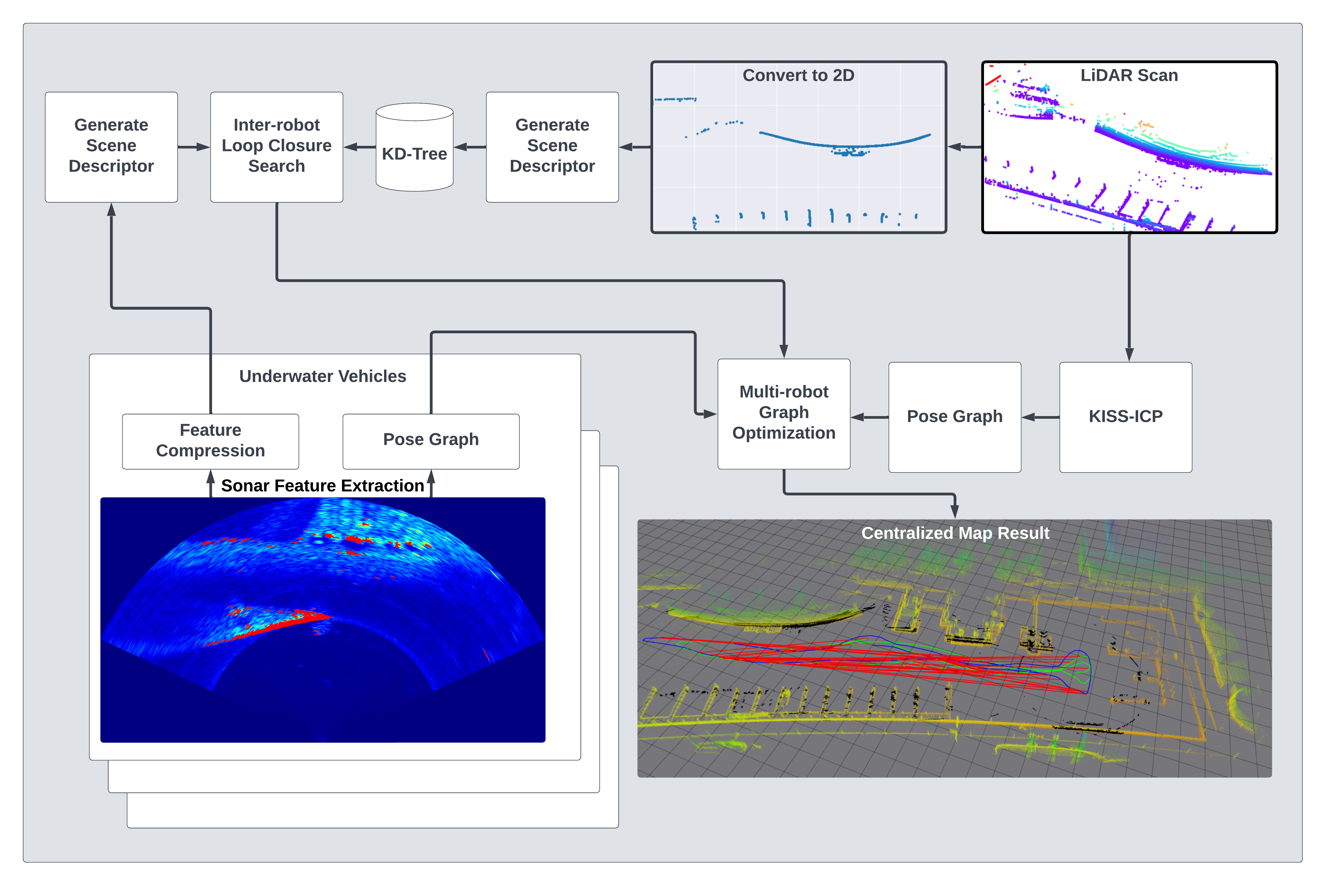
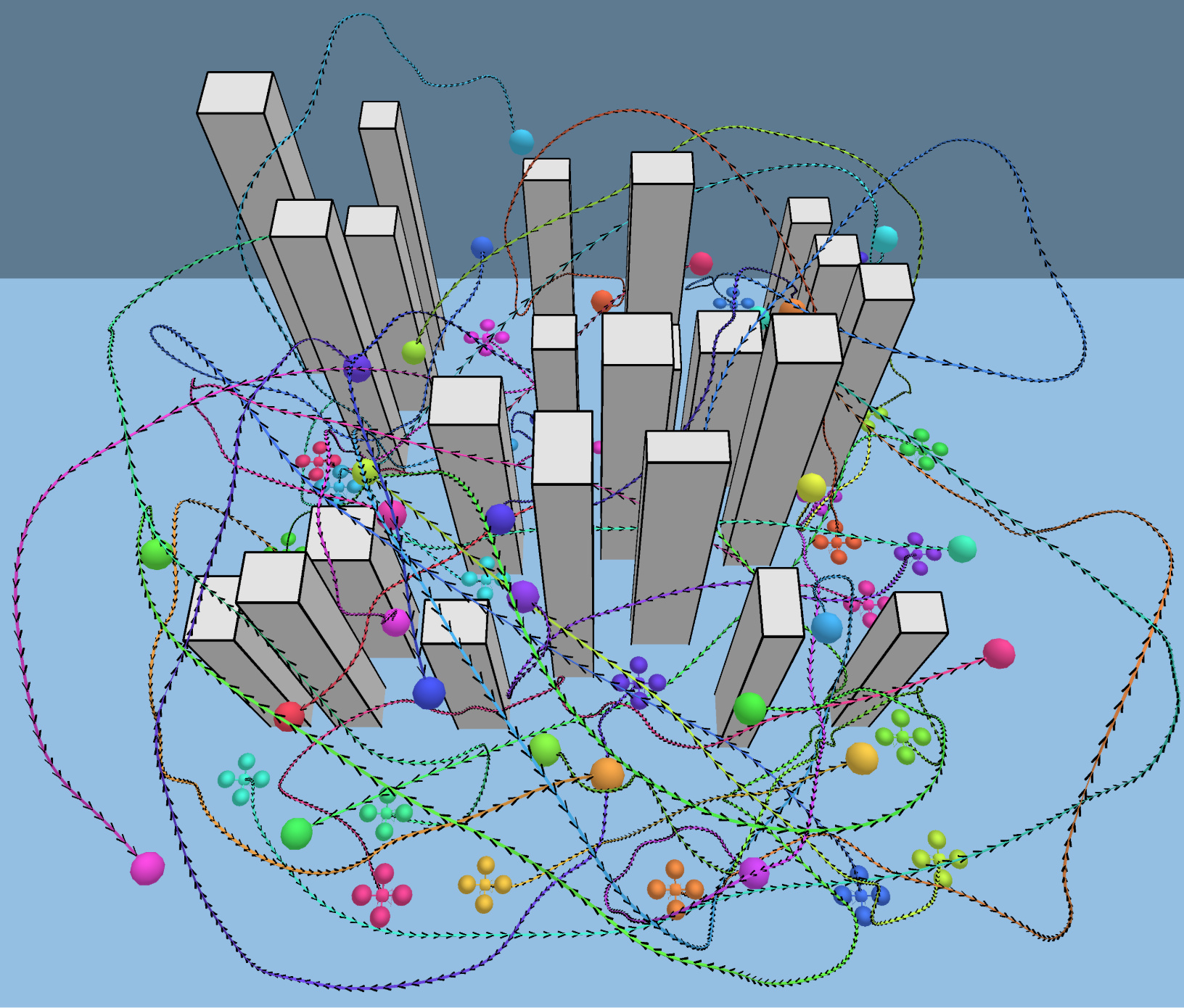
Each card carries a 2–3 sentence LLM-written summary of the source — read the gist here, click the title for the original. Summaries can occasionally be inaccurate, so verify details at the source.
Search by keyword, or click chips to filter. Method and Platform stack (e.g. #VLA + #Humanoid = VLA work on humanoids). Source and Time apply on top.
Sort by — Score (default): Code & Papers rank by relevance (topic match, released code, GitHub stars/forks, real-robot results, recency); News is grouped by priority tier (High → Mid → Low), newest within each. Created = newest first, Pushed = most recently updated, Stars = most-starred. (When the News source is selected, Pushed/Stars are hidden.)
Priority — the colored bar on each card's left edge reflects how relevant the item is (research-topic match, released code, real-robot results, recency, GitHub stars):
- High — strong signal: code or real-robot results and a close fit to robot-learning topics.
- Mid — moderately relevant; worth a glance.
- Low — weak or only loosely related.
Survey — pick Survey in the Source row to see only curated awesome-list / paper-list / survey / notes GitHub repos (purple SURVEY badge). They're maps of the field rather than runnable code, so they don't carry a High/Mid badge and the GitHub source view excludes them so it stays code-only.